技术文档收录
ASCII
Tcpdump
IPV4保留地址段
深入理解以太网网线原理 - 三帛的世界
白话 OSI 七层网络模型
Linux
WireGuard 一键安装脚本 | 秋水逸冰
SSH Config 那些你所知道和不知道的事 | Deepzz's Blog
Linux 让终端走代理的几种方法
ubuntu 20.04 server 版设置静态 IP 地址 - 链滴
Linux 挂载 Windows 共享磁盘的方法 - 技术学堂
将 SMB/CIFS 网络硬盘永久的挂载到 Ubuntu 上 - 简书
linux 获取当前脚本的绝对路径 | aimuke
[Linux] Linux 使用 / dev/urandom 生成随机数 - piaohua's blog
Linux 生成随机数的多种方法 | Just Do It
Linux 的 Centos7 版本下忘记 root 或者普通用户密码怎么办?
Git 强制拉取覆盖本地
SSH 安全加固指南 - FreeBuf 网络安全行业门户
Linux 系统安全强化指南 - FreeBuf 网络安全行业门户
Linux 入侵排查 - FreeBuf 网络安全行业门户
sshd_config 配置详解 - 简书
SSH 权限详解 - SegmentFault 思否
CentOS 安装 node.js 环境 - SegmentFault 思否
如何在 CentOS 7 上安装 Node.js 和 npm | myfreax
几款 ping tcping 工具总结
OpenVpn 搭建教程 | Jesse's home
openvpn 一键安装脚本 - 那片云
OpenVPN 解决 每小时断线一次 - 爱开源
OpenVPN 路由设置 – 凤曦的小窝
OpenVPN 设置非全局代理 - 镜子的记录簿
TinyProxy 使用帮助 - 简书
Ubuntu 下使用 TinyProxy 搭建代理 HTTP 服务器_Linux_运维开发网_运维开发技术经验分享
Linux 软件包管理工具 Snap 常用命令 - 简书
linux systemd 参数详解
Systemd 入门教程:命令篇 - 阮一峰的网络日志
记一次 Linux 木马清除过程
rtty:在任何地方通过 Web 访问您的终端
02 . Ansible 高级用法 (运维开发篇)
终于搞懂了服务器为啥产生大量的 TIME_WAIT!
巧妙的 Linux 命令,再来 6 个!
77% 的 Linux 运维都不懂的内核问题,这篇全告诉你了
运维工程师必备:请收好 Linux 网络命令集锦
一份阿里员工的 Java 问题排查工具单
肝了 15000 字性能调优系列专题(JVM、MySQL、Nginx and Tomcat),看不完先收
作业调度算法(FCFS,SJF,优先级调度,时间片轮转,多级反馈队列) | The Blog Of WaiterXiaoYY
看了这篇还不会 Linux 性能分析和优化,你来打我
2019 运维技能风向标
更安全的 rm 命令,保护重要数据
求你了,别再纠结线程池大小了!
Linux sudo 详解 | 失落的乐章
重启大法好!线上常见问题排查手册
sudo 使用 - 笨鸟教程的博客 | BY BenderFly
shell 在手分析服务器日志不愁? - SegmentFault 思否
sudo 与 visudo 的超细用法说明_陈发哥 007 的技术博客_51CTO 博客
ESXI 下无损扩展 Linux 硬盘空间 | Naonao Blog
Linux 学习记录:su 和 sudo | Juntao Tan 的个人博客
使用者身份切换 | Linux 系统教程(笔记)
你会使用 Linux 编辑器 vim 吗?
在 Windows、Linux 和 Mac 上查看 Wi-Fi 密码
linux 隐藏你的 crontab 后门 - 简书
Linux 定时任务详解 - Tr0y's Blog
linux 的 TCP 连接数量最大不能超过 65535 个吗,那服务器是如何应对百万千万的并发的?_一口 Linux 的博客 - CSDN 博客_tcp 连接数多少正常
万字长文 + 28 张图,一次性说清楚 TCP,运维必藏
为什么 p2p 模式的 tunnel 底层通常用 udp 而不是 tcp?
记一次服务器被入侵挖矿 - tlanyan
shell 判断一个变量是否为空方法总结 - 腾讯云开发者社区 - 腾讯云
系统安装包管理工具 | Escape
编译代码时动态地链接库 - 51CTO.COM
甲骨文 Oracle Cloud 添加新端口开放的方法 - WirelessLink 社区
腾讯云 Ubuntu 添加 swap 分区的方法_弓弧名家_玄真君的博客 - CSDN 博客
Oracle 开放全部端口并关闭防火墙 - 清~ 幽殇
谁再说不熟悉 Linux 命令, 就把这个给他扔过去!
即插即用,运维工程师必会正则表达式大全
Shell脚本编写及常见面试题
Samba 文件共享服务器
到底一台服务器上最多能创建多少个 TCP 连接 | plantegg
SSH 密钥登录 - SSH 教程 - 网道
在 Bash 中进行 encodeURIComponent/decodeURIComponent | Harttle Land
使用 Shell 脚本来处理 JSON - Tom CzHen's Blog
Docker
「Docker」 - 保存镜像 - 知乎
终于可以像使用 Docker 一样丝滑地使用 Containerd 了!
私有镜像仓库选型:Harbor VS Quay - 乐金明的博客 | Robin Blog
exec 与 entrypoint 使用脚本 | Mr.Cheng
Dockerfile 中的 CMD 与 ENTRYPOINT
使用 Docker 配置 MySQL 主从数据库 - 墨天轮
Alpine vs Distroless vs Busybox – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
再见,Docker!
docker save 与 docker export 的区别 - jingsam
如何优雅的关闭容器
docker 储存之 tmpfs 、bind-mounts、volume | 陌小路的个人博客
Dockerfile 中 VOLUME 与 docker -v 的区别是什么 - 开发技术 - 亿速云
理解 docker 容器的退出码 | Vermouth | 博客 | docker | k8s | python | go | 开发
【Docker 那些事儿】容器监控系统,来自 Docker 的暴击_飞向星的客机的博客 - CSDN 博客
【云原生】Docker 镜像详细讲解_微枫 Micromaple 的博客 - CSDN 博客_registry-mirrors
【云原生】Helm 架构和基础语法详解
CMD 和 Entrypoint 命令使用变量的用法
实时查看容器日志 - 苏洋博客
Traefik 2 使用指南,愉悦的开发体验 - 苏洋博客
为你的 Python 应用选择一个最好的 Docker 映像 | 亚马逊 AWS 官方博客
【云原生】镜像构建实战操作(Dockerfile)
Docker Compose 中的 links 和 depends_on 的区别 - 编程知识 - 白鹭情
Python
Pipenv:新一代Python项目环境与依赖管理工具 - 知乎
Python list 列表实现栈和队列
Python 各种排序 | Lesley's blog
Python 中使用 dateutil 模块解析时间 - SegmentFault 思否
一个小破网站,居然比 Python 官网还牛逼
Python 打包 exe 的王炸 - Nuitka
Django - - 基础 - - Django ORM 常用查询语法及进阶
[Python] 小知識:== 和 is 的差異 - Clay-Technology World
Window
批处理中分割字符串 | 网络进行时
Windows 批处理基础命令学习 - 简书
在Windows上设置WireGuard
Windows LTSC、LTSB、Server 安装 Windows Store 应用商店
windows 重启 rdpclip.exe 的脚本
中间件
Nginx 中的 Rewrite 的重定向配置与实践
RabbitMQ 的监控
RabbitMq 最全的性能调优笔记 - SegmentFault 思否
为什么不建议生产用 Redis 主从模式?
高性能消息中间件——NATS
详解:Nginx 反代实现 Kibana 登录认证功能
分布式系统关注点:仅需这一篇,吃透 “负载均衡” 妥妥的
仅需这一篇,妥妥的吃透” 负载均衡”
基于 nginx 实现上游服务器动态自动上下线——不需 reload
Nginx 学习书单整理
最常见的日志收集架构(ELK Stack)
分布式之 elk 日志架构的演进
CAT 3.0 开源发布,支持多语言客户端及多项性能提升
Kafka 如何做到 1 秒处理 1500 万条消息?
Grafana 与 Kibana
ELK 日志系统之通用应用程序日志接入方案
ELK 简易 Nginx 日志系统搭建: ElasticSearch+Kibana+Filebeat
记一次 Redis 连接池问题引发的 RST
把 Redis 当作队列来用,你好大的胆子……
Redis 最佳实践:业务层面和运维层面优化
Redis 为什么变慢了?常见延迟问题定位与分析
好饭不怕晚,扒一下 Redis 配置文件的底 Ku
rabbitmq 集群搭建以及万级并发下的性能调优
别再问我 Redis 内存满了该怎么办了
Nginx 状态监控及日志分析
uWSGI 的安装及配置详解
uwsgi 异常服务器内存 cpu 爆满优化思路
Uwsgi 内存占用过多 - 简书
Nginx 的 limit 模块
Nginx 内置模块简介
Redis 忽然变慢了如何排查并解决?_redis_码哥字节_InfoQ 写作社区
领导:谁再用 redis 过期监听实现关闭订单,立马滚蛋!
Nginx 限制 IP 访问频率以及白名单配置_问轩博客
Nginx $remote_addr 和 $proxy_add_x_forwarded_for 变量详解
Caddy 部署实践
一文搞定 Nginx 限流
数据库
SqlServer 将数据库中的表复制到另一个数据库_MsSql_脚本之家
SQL Server 数据库同步,订阅、发布、复制、跨服务器
sql server 无法删除本地发布 | 辉克's Blog
SQLite全文检索
SQL 重复记录查询的几种方法 - 简书
SQL SERVER 使用订阅发布同步数据库(转)
Mysql 查看用户连接数配置及每个 IP 的请求情况 - 墨天轮
优化 SQL 的 21 条方案
SQL Server 连接时好时坏的奇怪问题
MS SQL 执行大脚本文件时,提示 “内存不足” 的解决办法 - 阿里云开发者社区
防火墙-iptables
iptables 常用规则:屏蔽 IP 地址、禁用 ping、协议设置、NAT 与转发、负载平衡、自定义链
防火墙 iptables 企业防火墙之 iptables
Linux 防火墙 ufw 简介
在 Ubuntu 中用 UFW 配置防火墙
在 Ubuntu20.04 上怎样使用 UFW 配置防火墙 - 技术库存网
监控类
开箱即用的 Prometheus 告警规则集
prometheus☞搭建 | zyh
docker 部署 Prometheus 监控服务器及容器并发送告警 | chris'wang
PromQL 常用命令 | LRF 成长记
prometheus 中使用 python 手写 webhook 完成告警
持续集成CI/CD
GitHub Actions 的应用场景 | 记录干杯
GithubActions · Mr.li's Blog
工具类
GitHub 中的开源网络广告杀手,十分钟快速提升网络性能
SSH-Auditor:一款 SHH 弱密码探测工具
别再找了,Github 热门开源富文本编辑器,最实用的都在这里了 - srcmini
我最喜欢的 CLI 工具
推荐几款 Redis 可视化工具
内网代理工具与检测方法研究
环境篇:数据同步工具 DataX
全能系统监控工具 dstat
常用 Web 安全扫描工具合集
给你一款利器!轻松生成 Nginx 配置文件
教程类
Centos7 搭建神器 openvpn | 运维随笔
搭建 umami 收集个人网站统计数据 | Reorx’s Forge
openvpn安装教程
基于 gitea+drone 完成小团队的 CI/CD - 德国粗茶淡饭
将颜色应用于交替行或列
VMware Workstation 全系列合集 精简安装注册版 支持 SLIC2.6、MSDM、OSX 更新 16.2.3_虚拟机讨论区_安全区 卡饭论坛 - 互助分享 - 大气谦和!
在 OpenVPN 上启用 AD+Google Authenticator 认证 | 运维烂笔头
Github 进行 fork 后如何与原仓库同步:重新 fork 很省事,但不如反复练习版本合并 · Issue #67 · selfteaching/the-craft-of-selfteaching
卧槽,VPN 又断开了!!- 阿里云开发者社区
Grafana Loki 学习之踩坑记
zerotier 的 planet 服务器(根服务器)的搭建踩坑记。无需 zerotier 官网账号。
阿里云 qcow2 镜像转 vmdk,导入 ESXi - 唐际忠的博客
Caddy 入门 – 又见杜梨树
【Caddy2】最新 Caddy2 配置文件解析 - Billyme 的博客
Web 服务器 Caddy 2 | Haven200
手把手教你打造高效的 Kubernetes 命令行终端
Keras 作者:给软件开发者的 33 条黄金法则
超详细的网络抓包神器 Tcpdump 使用指南
使用 fail2ban 和 FirewallD 黑名单保护你的系统
linux 下 mysql 数据库单向同步配置方法分享 (Mysql)
MySQL 快速删除大量数据(千万级别)的几种实践方案
GitHub 上的优质 Linux 开源项目,真滴牛逼!
WireGuard 教程:使用 Netmaker 来管理 WireGuard 的配置 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
Tailscale 基础教程:Headscale 的部署方法和使用教程 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang | 云原生
Nebula Graph 的 Ansible 实践
改进你的 Ansible 剧本的 4 行代码
Caddy 2 快速简单安装配置教程 – 高玩梁的博客
切换至 Caddy2 | 某不科学的博客
Caddy2 简明教程 - bleem
树莓派安装 OpenWrt 突破校园网限制 | Asttear's Blog
OpenVPN 路由设置 – 凤曦的小窝
个性化编译 LEDE 固件
盘点各种 Windows/Office 激活工具
[VirtualBox] 1、NAT 模式下端口映射
VirtualBox 虚拟机安装 openwrt 供本机使用
NUC 折腾笔记 - 安装 ESXi 7 - 苏洋博客
锐捷、赛尔认证 MentoHUST - Ubuntu 中文
How Do I Use A Client Certificate And Private Key From The IOS Keychain? | OpenVPN
比特记事簿: 笔记: 使用电信 TR069 内网架设 WireGuard 隧道异地组网
利用 GitHub API 获取最新 Releases 的版本号 | 这是只兔子
docsify - 生成文档网站简单使用教程 - SegmentFault 思否
【干货】Chrome 插件 (扩展) 开发全攻略 - 好记的博客
一看就会的 GitHub 骚操作,让你看上去像一位开源大佬
【计算机网络】了解内网、外网、宽带、带宽、流量、网速_墩墩分墩 - CSDN 博客
mac-ssh 配置 | Sail
如何科学管理你的密码
VirtualBox NAT 端口映射实现宿主机与虚拟机相互通信 | Shao Guoliang 的博客
CentOS7 配置网卡为静态 IP,如果你还学不会那真的没有办法了!
laisky-blog: 近期折腾 tailscale 的一些心得
使用 acme.sh 给 Nginx 安装 Let’ s Encrypt 提供的免费 SSL 证书 · Ruby China
acme 申请 Let’s Encrypt 泛域名 SSL 证书
从 nginx 迁移到 caddy
使用 Caddy 替代 Nginx,全站升级 https,配置更加简单 - Diamond-Blog
http.proxy - Caddy 中文文档
动手撸个 Caddy(二)| Caddy 命令行参数最全教程 | 飞雪无情的总结
Caddy | 学习笔记 - ijayer
Caddy 代理 SpringBoot Fatjar 应用上传静态资源
使用 graylog3.0 收集 open××× 日志进行审计_年轻人,少吐槽,多搬砖的技术博客_51CTO 博客
提高国内访问 github 速度的 9 种方法! - SegmentFault 思否
VM16 安装 macOS 全网最详细
2022 目前三种有效加速国内 Github
How to install MariaDB on Alpine Linux | LibreByte
局域网内电脑 - ipad 文件共享的三种方法 | 岚
多机共享键鼠软件横向测评 - 尚弟的小笔记
VLOG | ESXI 如何升级到最新版,无论是 6.5 还是 6.7 版本都可以顺滑升级。 – Vedio Talk - VLOG、科技、生活、乐分享
远程修改 ESXi 6.7 管理 IP 地址 - 腾讯云开发者社区 - 腾讯云
几乎不要钱自制远程 PLC 路由器方案
traefik 简易入门 | 个人服务器运维指南 | 山月行
更完善的 Docker + Traefik 使用方案 - 苏洋博客
MicroSD·TF 卡终极探秘 ·MLC 颗粒之谜 1 三星篇_microSD 存储卡_什么值得买
macOS 绕过公证和应用签名方法 - 走客
MiscSecNotes / 内网端口转发及穿透. md at master · JnuSimba/MiscSecNotes
我有特别的 DNS 配置和使用技巧 | Sukka's Blog
SEO:初学者完整指南
通过 OpenVPN 实现流量审计
OpenVPN-HOWTO
OpenVPN Server · Devops Roadmap
Linux 运维必备的 13 款实用工具, 拿好了~
linux 平台下 Tomcat 的安装与优化
Linux 运维跳槽必备的 40 道面试精华题
Bash 脚本进阶,经典用法及其案例 - alonghub - 博客园
推荐几个非常不错的富文本编辑器 - 走看看
在 JS 文件中加载 JS 文件的方法 - 月光博客
#JavaScript 根据需要动态加载脚本并设置自定义参数
笔记本电脑 BIOS 修改及刷写教程
跨平台加密 DNS 和广告过滤 personalDNSfilter · LinuxTOY
AdGuard Home 安装及使用指北
通过 Amazon S3 协议挂载 OSS
记一次云主机如何挂载对象存储
(续)acme.sh 脚本使用新 cloudflare api 令牌申请证书 - 世界你好
本文档发布于https://mrdoc.fun
-
+
首頁
优化 SQL 的 21 条方案
一、查询 SQL 尽量不要使用 select *,而是具体字段 ------------------------------- 1、反例 ``` SELECT * FROM user<br style="visibility: visible;"> ``` 2、正例 ``` SELECT id,username,tel FROM user<br style="visibility: visible;"> ``` 3、理由 1. 节省资源、减少网络开销。 2. 可能用到覆盖索引,减少回表,提高查询效率。 `注意:为节省时间,下面的样例字段都用*代替了。` 二、避免在 where 子句中使用 or 来连接条件 -------------------------- 1、反例 ``` SELECT * FROM user WHERE id=1 OR salary=5000<br style="visibility: visible;"> ``` 2、正例 (1)使用 union all ``` SELECT * FROM user WHERE id=1 <br style="visibility: visible;">UNION ALL<br style="visibility: visible;">SELECT * FROM user WHERE salary=5000<br style="visibility: visible;"> ``` (2)分开两条 sql 写 ``` SELECT * FROM user WHERE id=1 SELECT * FROM user WHERE salary=5000 ``` 3、理由 1. 使用`or`可能会使索引失效,从而全表扫描; 2. 对于`or`没有索引的`salary`这种情况,假设它走了`id`的索引,但是走到`salary`查询条件时,它还得全表扫描; 3. 也就是说整个过程需要三步:全表扫描 + 索引扫描 + 合并。如果它一开始就走全表扫描,直接一遍扫描就搞定; 4. 虽然`mysql`是有优化器的,出于效率与成本考虑,遇到`or`条件,索引还是可能失效的; 三、尽量使用数值替代字符串类型 --------------- 1、正例 1. 主键(id):`primary key`优先使用数值类型`int`,`tinyint` 2. 性别(sex):0 代表女,1 代表男;数据库没有布尔类型,`mysql`推荐使用`tinyint` 2、理由 1. 因为引擎在处理查询和连接时会逐个比较字符串中每一个字符; 2. 而对于数字型而言只需要比较一次就够了; 3. 字符会降低查询和连接的性能,并会增加存储开销; 四、使用 varchar 代替 char -------------------- 1、反例 ``` `address` char(100) DEFAULT NULL COMMENT '地址' ``` 2、正例 ``` `address` varchar(100) DEFAULT NULL COMMENT '地址' ``` 3、理由 1. `varchar`变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间; 2. `char`按声明大小存储,不足补空格; 3. 其次对于查询来说,在一个相对较小的字段内搜索,效率更高; 五、技术延伸,char 与 varchar2 的区别? --------------------------- 1、`char`的长度是固定的,而`varchar2`的长度是可以变化的。 比如,存储字符串`“101”`,对于`char(10)`,表示你存储的字符将占 10 个字节(包括 7 个空字符),在数据库中它是以空格占位的,而同样的`varchar2(10)`则只占用 3 个字节的长度,10 只是最大值,当你存储的字符小于 10 时,按实际长度存储。 2、`char`的效率比`varchar2`的效率稍高。 3、何时用`char`,何时用`varchar2`? `char`和`varchar2`是一对矛盾的统一体,两者是互补的关系,`varchar2`比`char`节省空间,在效率上比`char`会稍微差一点,既想获取效率,就必须牺牲一点空间,这就是我们在数据库设计上常说的 “以空间换效率”。 `varchar2`虽然比`char`节省空间,但是假如一个`varchar2`列经常被修改,而且每次被修改的数据的长度不同,这会引起 “行迁移” 现象,而这造成多余的 I/O,是数据库设计中要尽力避免的,这种情况下用`char`代替`varchar2`会更好一些。`char`中还会自动补齐空格,因为你`insert`到一个`char`字段自动补充了空格的, 但是`select`后空格没有删除,因此`char`类型查询的时候一定要记得使用`trim`,这是写本文章的原因。 如果开发人员细化使用`rpad()`技巧将绑定变量转换为某种能与`char`字段相比较的类型(当然,与截断`trim`数据库列相比,填充绑定变量的做法更好一些,因为对列应用函数`trim`很容易导致无法使用该列上现有的索引),可能必须考虑到经过一段时间后列长度的变化。如果字段的大小有变化,应用就会受到影响,因为它必须修改字段宽度。 正是因为以上原因,定宽的存储空间可能导致表和相关索引比平常大出许多,还伴随着绑定变量问题,所以无论什么场合都要避免使用 char 类型。 六、where 中使用默认值代替 null --------------------- 1、反例 ``` SELECT * FROM user WHERE age IS NOT NULL ``` 2、正例 ``` SELECT * FROM user WHERE age>0 ``` 3、理由 1. 并不是说使用了`is null`或者`is not null`就会不走索引了,这个跟`mysql`版本以及查询成本都有关; 2. 如果`mysql`优化器发现,走索引比不走索引成本还要高,就会放弃索引,这些条件`!=,<>,is null,is not null`经常被认为让索引失效; 3. 其实是因为一般情况下,查询的成本高,优化器自动放弃索引的; 4. 如果把`null`值,换成默认值,很多时候让走索引成为可能,同时,表达意思也相对清晰一点; 七、避免在 where 子句中使用!= 或 <> 操作符 ---------------------------- 1、反例 ``` SELECT * FROM user WHERE salary!=5000 SELECT * FROM user WHERE salary<>5000 ``` 2、理由 1. 使用`!=`和`<>`很可能会让索引失效 2. 应尽量避免在`where`子句中使用`!=`或`<>`操作符,否则引擎将放弃使用索引而进行全表扫描 3. 实现业务优先,实在没办法,就只能使用,并不是不能使用 八、inner join 、left join、right join,优先使用 inner join -------------------------------------------------- 三种连接如果结果相同,优先使用 inner join,如果使用 left join 左边表尽量小。 * inner join 内连接,只保留两张表中完全匹配的结果集; * left join 会返回左表所有的行,即使在右表中没有匹配的记录; * right join 会返回右表所有的行,即使在左表中没有匹配的记录; 为什么? * 如果 inner join 是等值连接,返回的行数比较少,所以性能相对会好一点; * 使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少; * 这是 mysql 优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优; 九、提高 group by 语句的效率 ------------------- 1、反例 先分组,再过滤 ``` select job, avg(salary) from employee group by jobhaving job ='develop' or job = 'test'; ``` 2、正例 先过滤,后分组 ``` select job,avg(salary) from employee where job ='develop' or job = 'test' group by job; ``` 3、理由 可以在执行到该语句前,把不需要的记录过滤掉 十、清空表时优先使用 truncate ------------------- `truncate table`在功能上与不带`where`子句的`delete`语句相同:二者均删除表中的全部行。但`truncate table`比`delete`速度快,且使用的系统和事务日志资源少。 `delete`语句每次删除一行,并在事务日志中为所删除的每行记录一项。`truncate table`通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。 `truncate table`删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用`drop table`语句。 对于由`foreign key`约束引用的表,不能使用`truncate table`,而应使用不带 `where`子句的 DELETE 语句。由于`truncate table`不记录在日志中,所以它不能激活触发器。 `truncate table`不能用于参与了索引视图的表。 十一、操作 delete 或者 update 语句,加个 limit 或者循环分批次删除 -------------------------------------------- 1、降低写错 SQL 的代价 清空表数据可不是小事情,一个手抖全没了,删库跑路?如果加 limit,删错也只是丢失部分数据,可以通过 binlog 日志快速恢复的。 2、SQL 效率很可能更高 SQL 中加了`limit 1`,如果第一条就命中目标`return`, 没有`limit`的话,还会继续执行扫描表。 3、避免长事务 `delete`执行时, 如果`age`加了索引,MySQL 会将所有相关的行加写锁和间隙锁,所有执行相关行会被锁住,如果删除数量大,会直接影响相关业务无法使用。 4、数据量大的话,容易把 CPU 打满 如果你删除数据量很大时,不加 limit 限制一下记录数,容易把`cpu`打满,导致越删越慢。 5、锁表 一次性删除太多数据,可能造成锁表,会有 lock wait timeout exceed 的错误,所以建议分批操作。 十二、UNION 操作符 ------------ `UNION`在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表`UNION`。如: ``` select username,tel from user union select departmentname from department ``` 这个 SQL 在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。推荐方案:采用`UNION ALL`操作符替代`UNION`,因为`UNION ALL`操作只是简单的将两个结果合并后就返回。 十三、批量插入性能提升 ----------- 1、多条提交 ``` INSERT INTO user (id,username) VALUES(1,'哪吒编程');INSERT INTO user (id,username) VALUES(2,'妲己'); ``` 2、批量提交 ``` INSERT INTO user (id,username) VALUES(1,'哪吒编程'),(2,'妲己'); ``` 3、理由 默认新增 SQL 有事务控制,导致每条都需要事务开启和事务提交,而批量处理是一次事务开启和提交,效率提升明显,达到一定量级,效果显著,平时看不出来。 十四、表连接不宜太多,索引不宜太多,一般 5 个以内 -------------------------- 1、表连接不宜太多,一般 5 个以内 1. 关联的表个数越多,编译的时间和开销也就越大 2. 每次关联内存中都生成一个临时表 3. 应该把连接表拆开成较小的几个执行,可读性更高 4. 如果一定需要连接很多表才能得到数据,那么意味着这是个糟糕的设计了 5. 阿里规范中,建议多表联查三张表以下 2、索引不宜太多,一般 5 个以内 1. 索引并不是越多越好,虽其提高了查询的效率,但却会降低插入和更新的效率; 2. 索引可以理解为一个就是一张表,其可以存储数据,其数据就要占空间; 3. 索引表的数据是排序的,排序也是要花时间的; 4. `insert`或`update`时有可能会重建索引,如果数据量巨大,重建将进行记录的重新排序,所以建索引需要慎重考虑,视具体情况来定; 5. 一个表的索引数最好不要超过 5 个,若太多需要考虑一些索引是否有存在的必要; 十五、避免在索引列上使用内置函数 ---------------- 1、反例 ``` SELECT * FROM user WHERE DATE_ADD(birthday,INTERVAL 7 DAY) >=NOW(); ``` 2、正例 ``` SELECT * FROM user WHERE birthday >= DATE_ADD(NOW(),INTERVAL 7 DAY); ``` 3、理由 使用索引列上内置函数,索引失效。 十六、组合索引 ------- 排序时应按照组合索引中各列的顺序进行排序,即使索引中只有一个列是要排序的,否则排序性能会比较差。 ``` create index IDX_USERNAME_TEL on user(deptid,position,createtime);select username,tel from user where deptid= 1 and position = 'java开发' order by deptid,position,createtime desc; ``` 实际上只是查询出符合`deptid= 1 and position = 'java开发'`条件的记录并按 createtime 降序排序,但写成 order by createtime desc 性能较差。 十七、复合索引最左特性 ----------- 1、创建复合索引 ``` ALTER TABLE employee ADD INDEX idx_name_salary (name,salary) ``` 2、满足复合索引的最左特性,哪怕只是部分,复合索引生效 ``` SELECT * FROM employee WHERE NAME='哪吒编程' ``` 3、没有出现左边的字段,则不满足最左特性,索引失效 ``` SELECT * FROM employee WHERE salary=5000 ``` 4、复合索引全使用,按左侧顺序出现 name,salary,索引生效 ``` SELECT * FROM employee WHERE NAME='哪吒编程' AND salary=5000 ``` 5、虽然违背了最左特性,但 MySQL 执行 SQL 时会进行优化,底层进行颠倒优化 ``` SELECT * FROM employee WHERE salary=5000 AND NAME='哪吒编程' ``` 6、理由 复合索引也称为联合索引,当我们创建一个联合索引的时候,如 (k1,k2,k3),相当于创建了(k1)、(k1,k2) 和 (k1,k2,k3) 三个索引,这就是最左匹配原则。 联合索引不满足最左原则,索引一般会失效。 十八、优化 like 语句 ------------- 模糊查询,程序员最喜欢的就是使用`like`,但是`like`很可能让你的索引失效。 1、反例 ``` select * from citys where name like '%大连' (不使用索引) ``` ``` select * from citys where name like '%大连%' (不使用索引) ``` 2、正例 ``` select * from citys where name like '大连%' (使用索引) 。 ``` 3、理由 * 首先尽量避免模糊查询,如果必须使用,不采用全模糊查询,也应尽量采用右模糊查询, 即`like ‘…%’`,是会使用索引的; * 左模糊`like ‘%...’`无法直接使用索引,但可以利用`reverse + function index`的形式,变化成`like ‘…%’`; * 全模糊查询是无法优化的,一定要使用的话建议使用搜索引擎。 十九、使用 explain 分析你 SQL 执行计划 -------------------------- 1、type 1. system:表仅有一行,基本用不到; 2. const:表最多一行数据配合,主键查询时触发较多; 3. eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了 const 类型; 4. ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取; 5. range:只检索给定范围的行,使用一个索引来选择行。当使用 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,可以使用 range; 6. index:该联接类型与 ALL 相同,除了只有索引树被扫描。这通常比 ALL 快,因为索引文件通常比数据文件小; 7. all:全表扫描; 8. 性能排名:system > const > eq_ref > ref > range > index > all。 9. 实际 sql 优化中,最后达到 ref 或 range 级别。 2、Extra 常用关键字 * Using index:只从索引树中获取信息,而不需要回表查询; * Using where:WHERE 子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果 Extra 值不为 Using where 并且表联接类型为 ALL 或 index,查询可能会有一些错误。需要回表查询。 * Using temporary:mysql 常建一个临时表来容纳结果,典型情况如查询包含可以按不同情况列出列的`GROUP BY`和`ORDER BY`子句时; 二十、一些其它优化方式 ----------- 1、设计表的时候,所有表和字段都添加相应的注释。 2、SQL 书写格式,关键字大小保持一致,使用缩进。 3、修改或删除重要数据前,要先备份。 4、很多时候用 exists 代替 in 是一个好的选择 5、where 后面的字段,留意其数据类型的隐式转换。 未使用索引 ``` SELECT * FROM user WHERE NAME=110 ``` (1) 因为不加单引号时,是字符串跟数字的比较,它们类型不匹配; (2)MySQL 会做隐式的类型转换,把它们转换为数值类型再做比较; 6、尽量把所有列定义为`NOT NULL` `NOT NULL`列更节省空间,`NULL`列需要一个额外字节作为判断是否为`NULL`的标志位。`NULL`列需要注意空指针问题,`NULL`列在计算和比较的时候,需要注意空指针问题。 7、伪删除设计 8、数据库和表的字符集尽量统一使用 UTF8 (1)可以避免乱码问题; (2)可以避免,不同字符集比较转换,导致的索引失效问题; 9、select count(*) from table; 这样不带任何条件的 count 会引起全表扫描,并且没有任何业务意义,是一定要杜绝的。 10、避免在 where 中对字段进行表达式操作 (1)SQL 解析时,如果字段相关的是表达式就进行全表扫描 ; (2)字段干净无表达式,索引生效; 11、关于临时表 (1)避免频繁创建和删除临时表,以减少系统表资源的消耗; (2)在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log; (3)如果数据量不大,为了缓和系统表的资源,应先 create table,然后 insert; (4)如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除。先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定; 12、索引不适合建在有大量重复数据的字段上,比如性别,排序字段应创建索引 13、去重 distinct 过滤字段要少 1. 带 distinct 的语句占用`cpu`时间高于不带`distinct`的语句 2. 当查询很多字段时,如果使用`distinct`,数据库引擎就会对数据进行比较,过滤掉重复数据 3. 然而这个比较、过滤的过程会占用系统资源,如`cpu`时间 14、尽量避免大事务操作,提高系统并发能力 15、所有表必须使用`Innodb`存储引擎 `Innodb`「支持事务,支持行级锁,更好的恢复性」,高并发下性能更好,所以呢,没有特殊要求(即`Innodb`无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用`Innodb`存储引擎。 16、尽量避免使用游标 因为游标的效率较差,如果游标操作的数据超过 1 万行,那么就应该考虑改写。 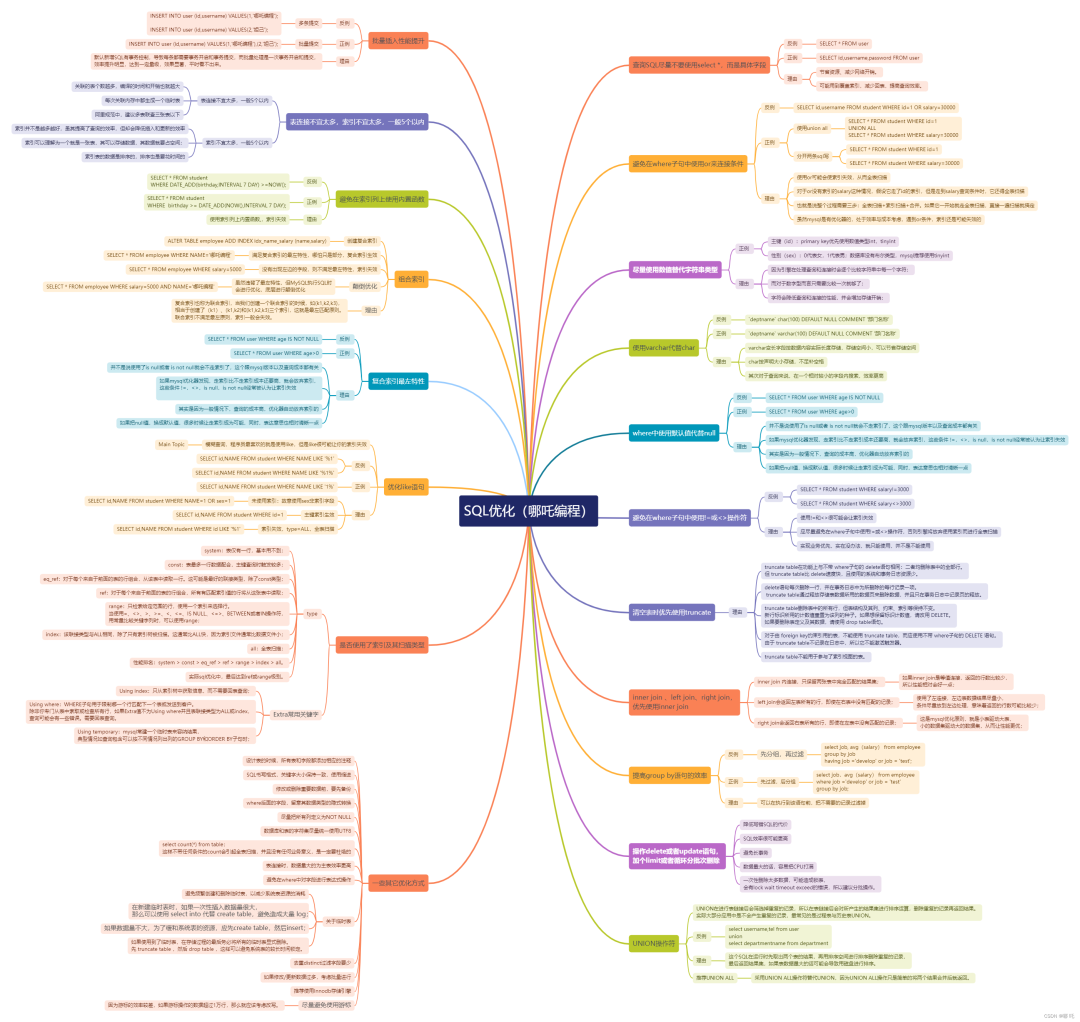 _链接:https://mp.weixin.qq.com/s/z8SQ5bvMBhKRgOZBDFS8oQ_ _(版权归原作者所有,侵删)_
Jonny
2022年10月16日 19:43
526
0 条评论
转发
收藏文檔
上一篇
下一篇
手机扫码
複製鏈接
手机扫一扫转发分享
複製鏈接
有些文档可能失效,请自行甄别!
【腾讯云】2核2G云服务器新老同享 99元/年,续费同价
【阿里云】2核2G云服务器新老同享 99元/年,续费同价(不要✓自动续费)
【腾讯云】2核2G云服务器新老同享 99元/年,续费同价
【阿里云】2核2G云服务器新老同享 99元/年,续费同价(不要✓自动续费)
分享
鏈接
類型
密碼
更新密碼
有效期
Markdown文件
Word文件
PDF文档
PDF文档(打印)
